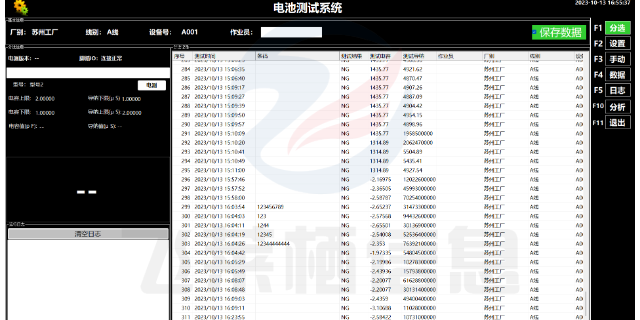
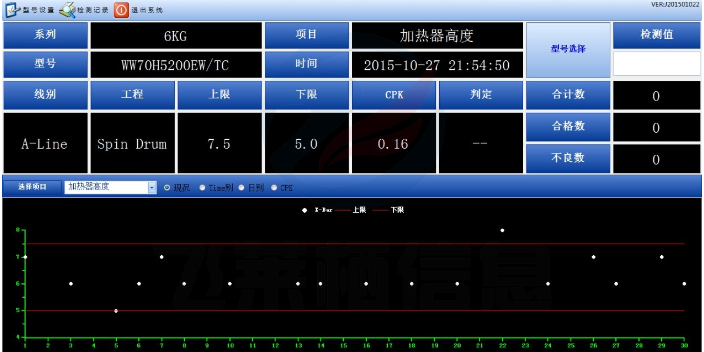
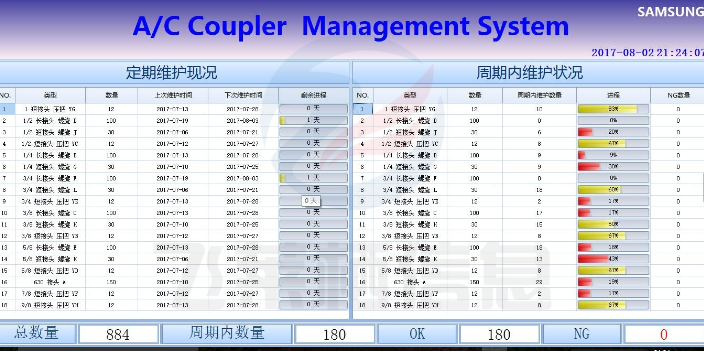
制造业数据采集单价
(2)磁卡磁卡是一种卡片状的磁性记录介质,利用磁性载体记录字符与数字信息,用来保存身份信息。视使用基材的不同。可分为PET卡、PVC卡和纸卡三种;视磁层构造的不同,又可分为磁条卡和全涂磁卡两种。磁卡的优点是成本低,这是它容易推广的原因,但缺点也比较明显,例如卡的保密性和安全性较差,使用磁卡的应用系统需要有可靠的计算机系统和中心数据库的支持。(3)RFIDRFID(RadioFrequencyIdentification,无线射频识别)是一种非接触式的自动识别技术,通过无线射频方式进行非接触双向数据通信,利用无线射频方式对记录媒体(电子标签或射频卡)进行读写,从而达到识别目标和数据交换的目的。基于特别业务场景的需求,在RFID的基础上发展出了NFC(NearFieldCommunication,近场通信)。数据采集可以通过智能物流系统实现对物流路径和成本的实时优化。制造业数据采集单价
这是因为全埋点虽然可以自动采集点击搜索按钮的点击事件,但无法自动获取关键词并作为点击事件的属性,但也可以通过写一定的代码配合全埋点来满足;如果使用可视化埋点的方案,如果我们能实现动态属性关联,也能实现上面的埋点需求。因此,在数据采集领域,根本不存在什么银弹,即不存在普适的完美方案能够适合所有的应用场景。我们能够做的,是针对不同的应用场景,选择**合适的数据采集方案。当然了,虽然没有银弹,但是数据采集中还是有一些比较通用的原则供我们参考,我们总结为四个字,即大、全、细、时。大:充分考虑用户规模与数据规模的增长,做好数据资产积累的准备。全:多端采集,针对全量用户行为而非抽样,采集要贯穿用户使用产品的整个生命周期。细:尽可能采集足够***的属性与维度,尽量保存数据细节,让积累的数据资产更加质量。例如,从Who、When、Where、How、What这5个角度来采集用户行为数据。时:在技术条件与成本允许的情况下,尽可能地提高数据采集的时效性,从而提高后续数据应用的时效性。四、数据采集案例分析案例一:App与H5打通近年来,App的混合开发越来越流行,App与H5的打通需求也越来越迫切。那什么是App与H5打通呢?所谓“打通”。嘉兴哪些数据采集价格数据采集通常涉及数据存储、传输和处理等多个环节。
▲图2***代离线计算平台架构第二代架构从2012~2014年,在承载离线计算的基础上,扩展了平台能力,支持实时计算的需求,如图3所示。▲图3第二代实时计算平台架构在***代离线计算平台基础之上,我们融合Storm和Spark构建了第二代实时计算平台。主要的演进如下。1)集成Spark,离线计算比Hadoop性能更高。2)引入Storm,支持秒级/毫秒级的流式计算任务。3)建设了实时采集系统TDBank,数据采集实现从天级(T+1)到秒级的飞跃。4)支持资源和任务调度方面,平台支持离线与在线混合部署,任务容器化,资源管理的维度支持CPU、内存,以及网络与I/O,进一步提升了平台轻量化、敏捷性与灵活性,极大提升了平台利用率,降低了成本。第三代架构从2015~2019年,在通用大数据计算外,开始支持机器学习、深度学习等AI场景,BigData与AI在平台层面逐步融合,如图4所示。▲图4第三代机器学习计算平台在第二代实时计算平台基础上,自主研发了机器学习平台Angel,并以Angel为**构建第三代机器学习计算平台生态。主要演进如下。1)我们与北京大学合作,自主研发了高性能分布式机器学习平台。该平台支持十亿至百亿维度模型,支持数据并行及模型并行,支持在线训练。同时。
▷线上行为数据:页面数据、交互数据、表单数据、会话数据等。▷内容数据:应用日志、电子文档、机械数据、话音数据、社交传媒数据等。▷大数据的主要来源:1)商贸数据2)互联网数据3)传感器数据数据采集与大数据采集区别传统数据采集1.来源单一,数据量相对于大数据较小2.构造单一3.联系数据库和并行数据储藏室大数据的数据采集1.来源普遍,数据量庞大2.数据种类丰沛,包括结构化,半结构化,非结构化3.分布式数据库传统数据收集的缺乏传统的数据采集来源单一,且存储、管理和分析数据量也相对较小,大都使用关系型数据库和并行数据库房即可处置。对倚赖并行测算提升数据处理速度方面而言,传统的并行数据库技术追求高度一致性和容错性,根据CAP学说,难以确保其可用性和扩展性。大数据搜集新的方式▷系统日志采集方式很多互联网企业都有自己的海量数据采集工具,多用以系统日志收集,如Hadoop的Chukwa,Cloudera的Flume,Facebook的Scribe等,这些工具均使用分布式架构,能满足每秒数百MB的日志数据采集和传输需要。▷网络数据采集方式网络数据采集是指通过网络爬虫或网站公开API等方法从网站上得到数据信息。该方式可以将非结构化数据从网页中抽取出来。数据采集可以通过自动化过程实现,减少人工干预和错误。
如果这个年轻的父亲在卖场只能买到两件商品之一,则他很有可能会放弃购物而到另一家商店,直到可以一次同时买到啤酒与尿布为止。沃尔玛发现了这一独特的现象,开始在卖场尝试将啤酒与尿布摆放在相同的区域,让年轻的父亲可以同时找到这两件商品,并很快地完成购物;而沃尔玛超市也可以让这些客户一次购买两件商品、而不是一件,从而获得了很好的商品销售收入,这就是“啤酒与尿布”故事的由来。[7]当然“啤酒与尿布”的故事必须具有技术方面的支持。1993年美国学者Agrawal提出通过分析购物篮中的商品**,从而找出商品之间关联关系的关联算法,并根据商品之间的关系,找出客户的购买行为。艾格拉沃从数学及计算机算法角度提出了商品关联关系的计算方法——Aprior算法。沃尔玛从上个世纪90年代尝试将Aprior算法引入到POS机数据分析中,并获得了成功,于是产生了“啤酒与尿布”的故事。[7]2、Suncorp-Metway使用数据分析实现智慧营销Suncorp-Metway是澳大利亚一家提供普通保险、银行业、寿险和理财服务的多元化金融服务集团,旗下拥有5个业务部门,管理着14类商品,由公司及共享服务部门提供支持,其在澳大利亚和新西兰的运营业务与900多万名客户有合作关系。数据收集可以通过自动化系统或手动方法进行。淮安光学数据采集系统
数据采集技术可以应用于个人健康管理,例如运动监测和饮食记录。制造业数据采集单价
全埋点优点如下:(1)前期埋点成本相对较低;(2)若分析需求或事件设计发生变化,无需应用程序修改埋点和发版;(3)可以有效地解决“历史数据回溯”问题。同时,全埋点也有一些缺点:(1)由于技术方面的原因,对于一些复杂的操作,比如缩放、滚动等,很难做到***覆盖;(2)无法自动采集和业务相关的数据;(3)无法满足更精细化的分析需求;(4)各种兼容性方面的问题;(5)传输的数据量太大、浪费资源。3.可视化埋点所谓可视化埋点,即通过可视化的方式进行埋点。可视化埋点,一般需要依赖全埋点相关的技术。可视化埋点一般有两种表现方式:一是默认情况下,不进行任何埋点,然后通过可视化的方式进行圈选,圈选哪些就采集哪些。二是默认情况下,开启全埋点全部采集,然后通过可视化的方式对全埋点的事件进行重命名。比如,对于登录页面上的登录按钮,全埋点采集的事件名一般都是固定的,比如叫:$AppClick,借助于可视化埋点,我们就可以对$AppClick事件进行重命名,比如login。与代码埋点和全埋点相比,可视化埋点看起来非常酷炫,但它也有相应的优缺点。优点:比如整个埋点比较贴近业务场景,同时也降低了埋点的技术门槛。制造业数据采集单价
上一篇: 湖州智能化MES哪个好
下一篇: 镇江附近哪里有数据采集大概多少钱