南通工业数据采集二次开发
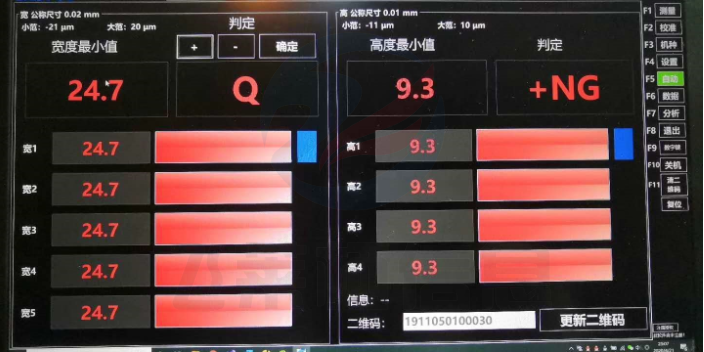
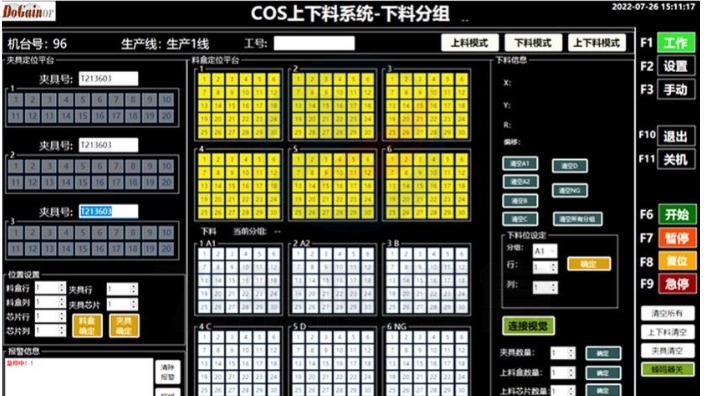
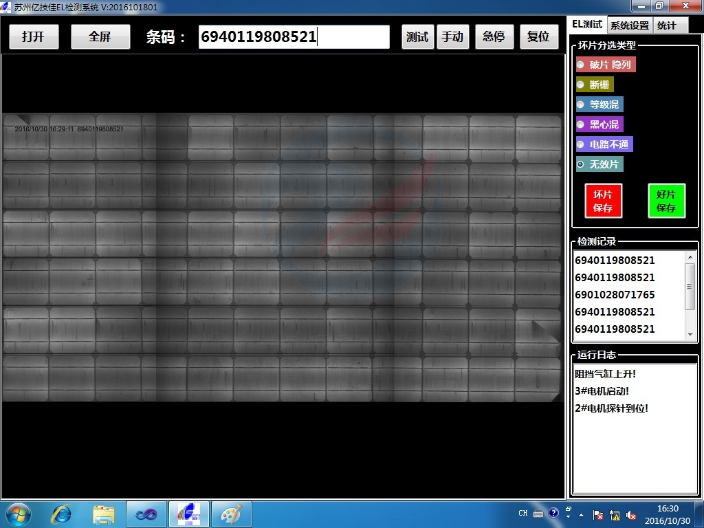
原则上应在每个CNC数据机床工位加装视觉图像识别系统,在吊钩上取得在制品放到工位上时进行视觉图像自动识别,系统识别后自动调用相关的加工程序到对应加工设备,如果考虑每台加工设备都加装视觉图像识别系统成本问题,可以考虑规划生产流水线。*在每流水线的特定位置加装一套识别系统,系统识别在制品后,能够通过流水线把相应在制品指定分配到对应的加工设备上,这样亦可进行自动装载程序,并且可以做到按CNC工位的繁忙情况智能均衡安排加工设备的生产任务,避免加工不同型号产品时刀具的反复切换带来的时间成本。数据采集可以通过智能制造系统实现对产品质量和生产效率的实时监控。南通工业数据采集二次开发
另外一个技术理念是:一切要为业务所用。我们固执地认为,技术如果不能为业务所用,那它就是毫无价值的。我们自主研发的Angel项目,出发点也是因为当时开源社区里面没有符合我们业务需求的机器学习平台,自主研发是因为对业务有价值,而不是因为它在技术上很有挑战性以及我们要证明自己技术很牛。Angel自2017年开源后有超过一百多个公司和组织使用,包括华为、小米、OPPO、新浪微博、拼多多等,发挥了Angel在腾讯以外的价值。02腾讯大数据的总体架构如前所述,腾讯大数据十余年的发展,经历了三代的技术演变,如图1所示。▲图1腾讯大数据三代技术演变***代架构从2009~2011年,以承载离线计算任务为主,如图2所示。TDW主要以Hadoop为基础构建,我们主要做了两方面的优化:其一扩大了集群规模,包括增强了集群拓展性,优化了调度性能,增强了容灾能力,通过差异化存储降低了存储成本;其二是利用周边生态降低应用门槛,建设配套的调度与开发平台,兼容Oracle的语法,以及集成PostgreSQL数据库以提升小数据量的分析性能。***代平台总结起来就是,技术上主要满足离线计算需求,技术挑战主要在不断扩展和优化集群规模,单集群规模从几十台到几百台,再到几千台不断突破。常州如何数据采集单价数据采集可以帮助企业优化产品设计和生产流程。
TimeSeriesDataBase,TSDB)专门从时间维度进行设计和优化,数据按时间顺序组织管理。图3-1所示为典型的时间序列数据,存储于关系型数据库中,当数据规模急剧增大时,关系型数据库的处理能力变得吃紧,需要性能更优的数据库。工业数据和互联网数据存在很大差别,前者通常是结构化的,而后者以非结构化数据为主。▲图3-1时间序列数据示例3.实时性工业数据采集的一个很大特点是实时性,包括数据采集的实时性以及数据处理的实时性。例如基于传感器的数据采集,其中一个重要指标为采样率,即每秒采集多少个点。采样率低的如温湿度采集,采样间隔在分钟级;采样率高一些的如振动信号,每秒钟采集几万个点甚至更多,方便后续信号分析处理以获得高阶谐波分量。有些大的科学装置,例如粒子加速器的束流监测系统,采样率达数兆每秒。采样率越高意味着单位时间数据量越大,如此大的数据量,如果不加处理直接通过网络传输到数据中心或云端,对于网络的带宽要求非常之高,而且如此大的带宽下,很难保证网络传输的可靠性,可能会产生非常大的传输时延。而部分工业物联网应用,如设备故障诊断、多机器人协作、状态监测等,由于要求在数据采集(感知)、分析、决策执行之间,完成快速闭环。
对事件里的属性内容进行二次加工,甚至是修正。一方面保证数据采集的准确性,另一方面保证数据的完整性。因为神策客户大多数采用私有化部署,神策难以统计用户数据丢失率,但是在业界普遍标准是“App的数据丢失率在1%左右,H5和Web的数据丢失率在5%左右”,之所以有5倍差异,是因为H5的本地缓存是有限的,数据上传失败就意味着丢失;另外,大多情况下H5在App中以单页面形式存在,H5发送网络请求之后,如果用户退出页面,其网络请求随之被取消,没有办法实现完全同步,这种情况下数据“打通”便朝着更高要求、高标准迈进——如何“打通”App与H5降低数据丢失率?App采集的事件并非实时同步,因为App内事件多、频率高,每次采集后立即同步会给服务器带来很大的压力,所以一般情况下,App内会增加本地缓存,所有采集到的事件先存入本地缓存,达到一定条件后再进行同步。也就是说,根据缓存制定相应的数据同步策略。如果按照以上方案,将H5的事件传给App进行二次加工,进入App端的本地缓存,走App端事件同步策略,就能**降低H5事件丢失的概率。这是我们在App与H5打通的第二版中着重处理的内容,在该解决方案中,不管是用户标识、数据准确性,还是数据完整性,都能得到解决。数据采集可以通过网络爬虫技术实现对互联网信息的抓取。
iOS一般使用IDFA或IDFV,H5一般使用Cookie),进而就会导致一个用户使用了我们的产品,结果产生了两个匿名用户的情况。如果App与H5打通,就可以将两个匿名ID做归一化处理(以App端匿名ID为准)。那如何打通呢?在实现App与H5打通的过程中,神策数据经历了三个阶段,相对应地设计三个方案以应对不同时期的需求。方案一:设想一个场景,你的App中嵌入了一个H5,如果用户启动App但没有进行注册或登录,这个时候该如何标识用户?我们可能会用匿名ID或者设备ID进行标记,但是H5和App的匿名ID生成规则是不一样的,H5常用的是Cookie;Android常用的是AndroidID,或者**近比较流行的OAID,或者UUID;在iOS系统中,我们常用的是IDFA,当IDFA被限制后,可以用IDFV。因此,不管是Android还是iOS,在跟H5进行混合的时候,用户在产品上没有注册或的登录的时候,会产生两个匿名ID,就相当于有两个匿名用户存在,这明显与实际不符。所以我们**初做数据打通时就面临着户标识的问题。在启动内嵌入H5的时候,主动把App端生成的匿名ID传给H5,这样H5产生的所有事件都可以用App传来的匿名ID进行标识,完成用户标识统一,这是2016年神策在处理App与H5打通的***版解决方案。通过数据采集,企业可以了解客户的需求和偏好,从而更好地满足他们的期望,提供个性化的产品和服务。扬州企业数据采集售价
数据采集可以通过智能保险系统实现对保险合规的实时监控。南通工业数据采集二次开发
[6]数据分析识别需求识别信息需求是确保数据分析过程有效性的首要条件,可以为收集数据、分析数据提供清晰的目标。识别信息需求是管理者的职责管理者应根据决策和过程控制的需求,提出对信息的需求。就过程控制而言,管理者应识别需求要利用那些信息支持评审过程输入、过程输出、资源配置的合理性、过程活动的优化方案和过程异常变异的发现。[6]数据分析收集数据有目的的收集数据,是确保数据分析过程有效的基础。组织需要对收集数数据分析示意图据的内容、渠道、方法进行策划。策划时应考虑:[6]①将识别的需求转化为具体的要求,如评价供方时,需要收集的数据可能包括其过程能力、测量系统不确定度等相关数据;[6]②明确由谁在何时何处,通过何种渠道和方法收集数据;[6]③记录表应便于使用;④采取有效措施,防止数据丢失和虚假数据对系统的干扰。[6]数据分析分析数据分析数据是将收集的数据通过加工、整理和分析、使其转化为信息,通常用方法有:[6]老七种工具,即排列图、因果图、分层法、调查表、散布图、直方图、控制图;[6]新七种工具,即关联图、系统图、矩阵图、KJ法、计划评审技术、PDPC法、矩阵数据图。[6]数据分析过程改进数据分析是质量管理体系的基础。南通工业数据采集二次开发
上一篇: 苏州附近哪里有数据采集方案
下一篇: 宿迁信息化数据采集供应商